
nvidia Tesla K80 24G
日期:2017-05-23 11:17:38 / 人(rén)氣: 1468

Tesla K80的(de)參數
Tesla K80 雙GPU 加速器可(kě)透過一卡雙 GPU 提供雙倍傳輸量,内置24GB GDDR5 存儲器,每顆 GPU 有 12GB 存儲器,比上代Tesla K40 GPU 提供多(duō)兩倍存儲器處理(lǐ)更大(dà)的(de)資料集分(fēn)析。Tesla K80 内建4,992 CUDA 平行運算(suàn)核心,可(kě)比僅用(yòng)CPU 運算(suàn)提升高(gāo)達10 倍應用(yòng)加速效能,加上采用(yòng)動态NVIDIA GPU Boost 技術,可(kě)根據個(gè)别應用(yòng)靈活提升GPU 時(shí)脈,而且更透過動态平行運算(suàn)架構,讓用(yòng)戶可(kě)快(kuài)速分(fēn)析關聯式和(hé)動态的(de)資料結構。
英偉達 NVIDIA Tesla K80 24GB GPU加速運算(suàn)卡
最高(gāo)實際性能
實際應用(yòng)性能高(gāo)于純浮點性能 (Raw Flops)。 計算(suàn)專業人(rén)士依賴舉足輕重的(de)應用(yòng)來(lái)加速探索與深入了(le)解。 這(zhè)一平台從全球最快(kuài)的(de)加速器開始,現已包含可(kě)靠的(de)基礎架構、監控和(hé)管理(lǐ)基礎架構的(de)能力以及在需要時(shí)快(kuài)速移動數據的(de)能力。 NVIDIA Tesla 加速計算(suàn)平台可(kě)提供所有這(zhè)些特性,在科學、分(fēn)析、工程、消費級以及企業應用(yòng)中帶來(lái)前所未有的(de)性能。
全球最快(kuài)的(de) GPU 加速器
- Tesla K80 GPU 加速器上的(de)雙精度性能高(gāo)達 2.91 TFlops,單精度性能高(gāo)達 8.74 TFlops
- 利用(yòng) NVIDIA® GPUBoost™ 技術時(shí)每一款應用(yòng)的(de)最高(gāo)性能
- 大(dà)容量闆載内存可(kě)提升大(dà)型數據集的(de)性能 (Tesla K80 GPU 加速器爲 24 GB)
- 極高(gāo)的(de)内存帶寬可(kě)提升吞吐量以便在需要時(shí)确保數據可(kě)用(yòng) (Tesla K80 GPU 加速器爲 480 GB/s)
- 糾錯碼(ECC)爲内部GPU内存提供了(le)強大(dà)的(de)數據可(kě)靠性并爲外部GDDR5内存提供了(le)ECC保護盒動态頁面引退機制。
用(yòng)于服務器的(de) TESLA K40 與 K80 GPU 加速器
利用(yòng) NVIDIA® Tesla® GPU 加速器爲你最苛刻的(de)數據分(fēn)析與科學計算(suàn)應用(yòng)加速。 Tesla GPU 基于 NVIDIA Kepler™ 架構,旨在提供更快(kuài)、更高(gāo)效的(de)計算(suàn)性能。
從能源勘探到機器學習(xí),數據科學家利用(yòng) Tesla 加速器可(kě)以輕松處理(lǐ)多(duō)達拍(pāi)字節 (Petabytes) 的(de)數據,而且速度比使用(yòng) CPU 時(shí)快(kuài) 10 倍。 對(duì)計算(suàn)科學家來(lái)說,Tesla 加速器可(kě)提供所需的(de)處理(lǐ)動力,能夠以前所未有的(de)速度運行更大(dà)型的(de)模拟。
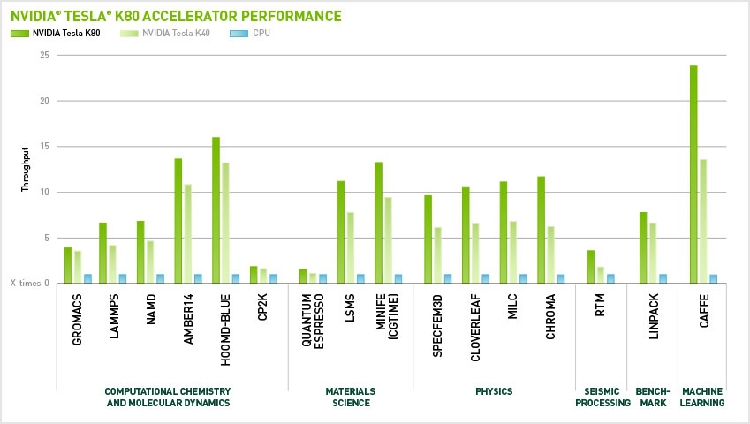
CPU: 12 cores, E5-2697v2 @ 2.70GHz. 64GB System Memory, CentOS 6.2. GPU: Single Tesla K80, Boost enabled or Single Tesla K40, Boost Enabled
SELECT THE TESLA GPU THAT'S RIGHT FOR YOU
Tesla K80 GPU 加速器
Tesla K80 GPU 是一款雙 GPU 卡,它把帶寬超高(gāo)的(de) 24 GB 内存和(hé)高(gāo)達 2.91 TFlops 的(de)雙精度性能與 NVIDIA GPUBoost™ 結合到了(le)一起,它是專爲最苛刻的(de)計算(suàn)任務而設計的(de)。 它十分(fēn)适合那些不但需要一流計算(suàn)性能而且還(hái)要求數據吞吐量大(dà)的(de)單精度和(hé)雙精度計算(suàn) 馬上免費試用(yòng)Tesla K80加速器.
Tesla K40 GPU 加速器
Tesla K40 加速器配有 12 GB 内存,可(kě)提供 1.43 TFlops 的(de)雙精度性能。 Tesla K40 加速器是一款用(yòng)于高(gāo)性能計算(suàn)與數據分(fēn)析的(de)靈活解決方案,它能夠毫不費力地運行高(gāo)性能計算(suàn)與數據分(fēn)析應用(yòng)。
選擇合适的(de) TESLA GPU
| 特性 | Tesla K801 | Tesla K40 |
| GPU | 2 顆 Kepler GK210 | 1 Kepler GK110B |
| 峰值雙精度浮點性能 |
2.91 Tflops (GPU 動态提速頻(pín)率) 1.87 Tflops (基礎頻(pín)率) |
1.66 Tflops (GPU 動态提速頻(pín)率) 1.43 Tflops (基礎頻(pín)率) |
| 峰值單精度浮點性能 |
8.74 Tflops (GPU 動态提速頻(pín)率) 5.6 Tflops (基礎頻(pín)率) |
5 Tflops (GPU 動态提速頻(pín)率) 4.29 Tflops (基礎頻(pín)率) |
| 存儲器帶寬 (ECC關閉)2 | 480 GB/s (每顆 GPU 240 GB/s) | 288 GB/sec |
| 存儲器容量 (GDDR5) | 24 GB (每顆 GPU 12GB) | 12 GB |
| CUDA 核心數量 | 4992 個(gè) (每顆 GPU 2496個(gè)) | 2880 |
1 所示的(de) Tesla K80 的(de)規格參數是兩顆 GPU 的(de)總和(hé)。
2 在啓用(yòng) ECC 的(de)情況下(xià),6.25%的(de) GPU 内存用(yòng)于 ECC 數據位。 例如,在啓用(yòng) ECC 的(de)情況下(xià),如果内存總容量爲 6 GB,那麽用(yòng)戶可(kě)用(yòng)内存容量爲 5.25 GB。
Tesla 軟件功能
NVIDIA® Tesla® GPU計算(suàn)産品專爲工作站以及數據中心的(de)高(gāo)性能計算(suàn)而設計。 有許多(duō) CUDA 軟件特性都是專爲 GPGPU 而設計的(de),而且隻有 Tesla 産品才支持這(zhè)些特性。 下(xià)表對(duì)此進行了(le)總結。
|
軟件應用(yòng)程序
|
描述 | 支持 Matrix | 下(xià)載 | ||||||||||||||||||
|
Windows 的(de)高(gāo)性能驅動程序: TCC 驅 動程序
|
|
|
|
||||||||||||||||||
|
GPU 監控: nvsmi
|
|
|
|
||||||||||||||||||
|
GPU 集群管理(lǐ)
|
|
|
|
||||||||||||||||||
|
NVIDIA GPUDirect™ v1.0
|
|
|
下(xià)載
|
||||||||||||||||||
|
NVIDIA GPUDirect™ v2.0
|
|
|
|
注: CUDA 注冊開發者 現在可(kě)以下(xià)載 CUDA 4.1 候選版本。
針對(duì) WINDOWS 的(de) TCC 驅動程序
TCC (Tesla 計算(suàn)機集群)驅動程序是一種用(yòng)于 CUDA C/C++ 的(de) Windows 驅動程序,該驅動程序可(kě)實現遠(yuǎn)程桌面、服務并能夠在 Windows 上減少 CUDA 内核啓動的(de)系統總開銷。 請注意,TCC 驅動程序可(kě)禁用(yòng) Tesla 産品上的(de)圖形功能。
GPU 監控
針對(duì) Tesl a的(de) GPU 監控軟件可(kě)以利用(yòng) nvsmi 工具來(lái)獲得(de)。 該工具目前能夠給出 GPU 溫度、風扇轉速以及 ECC 信息。 随著(zhe)我們新增更多(duō)的(de) GPU 監控特性,nvsmi 将不斷發展。
GPU 集群管理(lǐ)
NVIDIA® 與多(duō)家集群管理(lǐ)軟件供應商均保持著(zhe)合作關系,這(zhè)些供應商支持基于GPU 的(de)系統:
| – | Bright Computing |
| – | ClusterCorp Rocks |
| – | Platform Computing |
除了(le)這(zhè)些以外,CUDA 驅動程序還(hái)支持兩種重要的(de)特性:
| – | 排他(tā)模式: 隻讓特定應用(yòng)程序訪問某一 GPU |
| – | GPU 可(kě)視設備: 通(tōng)過控制應用(yòng)程序能夠使用(yòng)哪些 GPU,從而讓集群管理(lǐ)軟件能夠管理(lǐ) GPU 資源。 |
NVIDIA® GPUDIRECT™
通(tōng)過消除不必要的(de) CPU 處理(lǐ)時(shí)間,NVIDIA GPUDirect 技術讓 GPU 能夠與 PCIe 總線上的(de)其它設備更快(kuài)地通(tōng)信。 GPUDirect v1.0 讓第三方設備驅動程序 (例如用(yòng)于 InfiniBand 适配器的(de)驅動程序) 能夠直接與 CUDA 驅動程序通(tōng)信,消除了(le)在 CPU 上複制數據所需的(de)處理(lǐ)時(shí)間。 GPUDirect v2.0 讓同一系統中的(de)多(duō)個(gè) GPU 之間能夠實現點對(duì)點 (P2P) 通(tōng)信,避免了(le)額外的(de) CPU 處理(lǐ)時(shí)間。